Amazon S3
Scalable cloud object storage for distributed deployments CyborgDB supports Amazon S3 (and S3-compatible stores such as MinIO) as a backing store, enabling fully cloud-native deployments without managing a traditional database server.Key Benefits
Infinite ScalabilityObject storage scales seamlessly with your data — no capacity planning or provisioning required. Managed Infrastructure
No database servers to patch, tune, or back up. AWS handles availability and durability. S3-Compatible
Works with AWS S3, MinIO, Cloudflare R2, and any other S3-compatible object store. Best For: Cloud-native deployments, multi-region architectures, and workloads that already rely on object storage infrastructure.
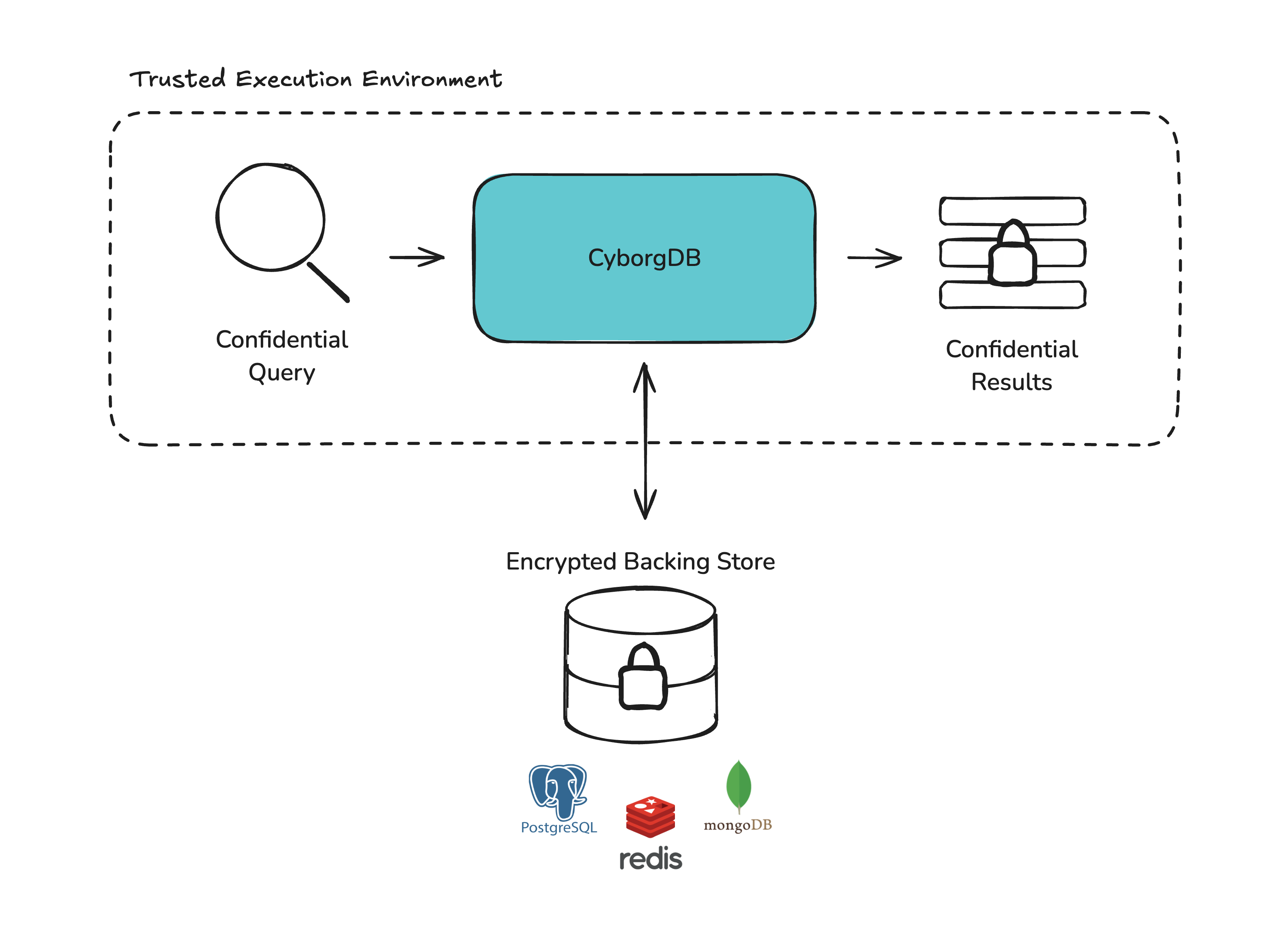
Standalone
For our embedded libraries, Standalone is referred to as “RocksDB”
Key Benefits
No Network Dependency All data is stored locally on disk — no external database servers to configure or manage. Persistent Storage Data survives process restarts with automatic durability via write-ahead logging. Optimized for Embedded Use Low memory footprint with filesystem support. Best For: Embedded/local deployments, single-machine applications, edge devices, and scenarios where you want persistent storage without external infrastructure.PostgreSQL
Production-ready relational database with vector extensions PostgreSQL provides robust data durability, ACID transactions, and excellent tooling ecosystem. CyborgDB leverages PostgreSQL’s reliability while adding encrypted vector search capabilities on top.Key Benefits
ACID ComplianceFull transactional consistency for mission-critical applications with guaranteed data integrity. Rich Ecosystem
Extensive tooling, monitoring, and operational expertise available across the industry. Enterprise Scalability
Support for read replicas, connection pooling, horizontal scaling, and mature backup solutions. Best For: Production applications requiring data consistency, teams with existing PostgreSQL expertise, and environments requiring strict data durability guarantees.
Redis
High-performance in-memory data store Redis delivers ultra-low latency access patterns, making it ideal for real-time applications. CyborgDB uses Redis’s memory-optimized storage for blazing-fast vector search operations.Key Benefits
Ultra-Low LatencySub-millisecond response times for vector queries with excellent concurrent access performance. High Throughput
Optimized for high-volume concurrent operations with flexible data structures beyond simple key-value storage. Configurable Persistence
Choose between speed and durability with flexible persistence and replication options. Best For: Real-time applications with strict latency requirements, high-throughput vector search workloads, and caching scenarios.
Memory
For our embedded libraries, Memory is referred to as “ThreadSafeMemory”
Key Benefits
Zero Network LatencyDirect memory access without serialization overhead for maximum performance. Development Simplicity
No external dependencies or configuration required - instant setup for prototyping. Deterministic Performance
Predictable access patterns with complete control over memory usage. Best For: Development and testing environments, single-process applications, proof-of-concept scenarios, and ephemeral data requirements.
Managed Services Support
CyborgDB works seamlessly with managed database services, reducing operational overhead while maintaining security and performance.AWS
Amazon S3
Scalable object storage with 11 nines of durabilityAmazon RDS for PostgreSQL
Fully managed PostgreSQL with automated backups and scalingAmazon ElastiCache for Redis
Managed Redis with cluster mode and automatic failover
Scalable object storage with 11 nines of durabilityAmazon RDS for PostgreSQL
Fully managed PostgreSQL with automated backups and scalingAmazon ElastiCache for Redis
Managed Redis with cluster mode and automatic failover
Azure
Azure Database for PostgreSQL
Managed PostgreSQL with built-in security and monitoringAzure Cache for Redis
Enterprise-grade managed Redis with geo-replication
Managed PostgreSQL with built-in security and monitoringAzure Cache for Redis
Enterprise-grade managed Redis with geo-replication
Google Cloud
Cloud SQL for PostgreSQL
Fully managed PostgreSQL with automatic maintenanceMemorystore for Redis
Secure and highly available managed Redis service
Fully managed PostgreSQL with automatic maintenanceMemorystore for Redis
Secure and highly available managed Redis service
Choosing the Right Backing Store
- Use RocksDB
- Use PostgreSQL
- Use Redis
- Use S3
- Use Memory
- Embedded Deployment - You want persistent local storage with no external dependencies
- Edge Devices - Running on hardware without network access to databases
- Simplicity - You want a single-binary deployment with built-in storage
- Local Development - Persistent storage that survives restarts without infrastructure
- Single Machine - Your application runs on a single machine
Configuration Examples
Performance Characteristics
| Backing Store | Latency | Throughput | Durability | Consistency |
|---|---|---|---|---|
| Memory | ~1µs | Very High | None | Single Process |
| ThreadSafeMemory | ~1µs | Very High | None | Thread-Safe |
| RocksDB | ~10µs | High | Local Disk | Single Process |
| Redis | ~100µs | High | Configurable | Eventually Consistent |
| S3 | ~10ms | Medium | Full (11 nines) | Eventual |
| PostgreSQL | ~1ms | Medium | Full | ACID |